
Modéliser une IA
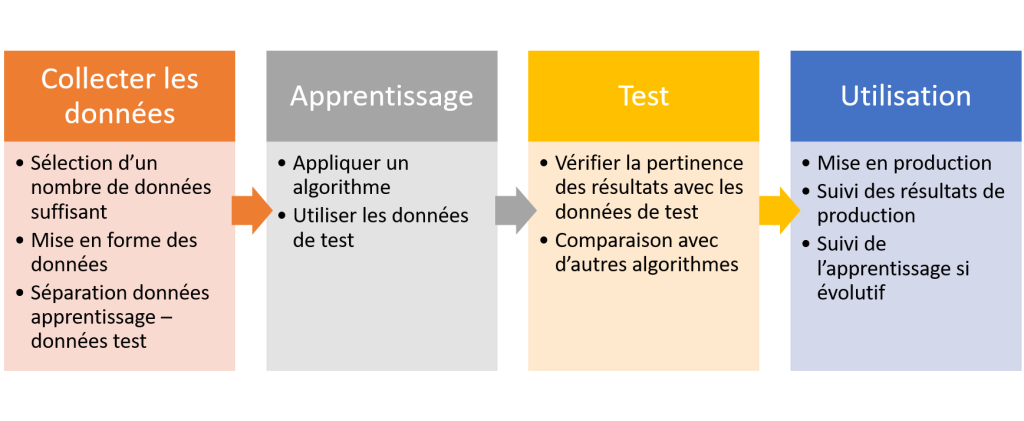
Toute IA, ou devrais-je dire, toute IA se basant sur du machine learning (ou du deep learning ou toute autre méthose basée sur l’apprentissage) se créée de la manière suivante :
- On recueille un jeu de données
- On divise le jeu de données en 2, une partie pour l’apprentissage, une partie pour les tests
- On utilise le jeu de données d’entrainement pour « apprendre » à notre IA les divers comportements et lui permettre de créer une modélisation
- On teste la pertinence du modèle grâce au jeu de données de test

Il est à noter qu’il est possible et recommander de mettre en concurrence différents algorithmes durant la phase d’apprentissage et de comparer leurs résultats.
Caractéristiques des données
Comme vous pouvez le constater le résultat dépend entièrement des données et il faut faire particulièrement attention à plusieurs points lorsque l’on sélectionne son jeu de données qui servira à l’apprentissage et au test.
Pour avoir une IA performante il faut donc :
- Avoir suffisamment de données pour permettre une modélisation et des tests. Un philosophe disait que le monticule de son savoir n’était rien par rapport à la montagne de son ignorance. Fort heureusement, ce « monticule » est suffisant pour les humains, pour avoir de bons résultats. Ces bons résultats sont explicables notamment grâce au contexte. Malheureusement pour l’IA, cette dernière ne connait pas encore la notion de contexte. Il lui faut donc, pour l’entrainer et lui permettre d’être efficace, lui offrir la montagne que nous humain ne pourront jamais analyser. Il faut donc lui offrir beaucoup de données ! Dans l’idéal, les logs de production (quand ils existent) sont les données les plus pertinentes.
- Avoir des données donnant une bonne couverture de ce que l’on souhaite évaluer ou prédire (ex : le comportement des utilisateurs). Il faut en effet avoir des données couvrant l’ensemble des parcours, informations ou actions à effectuer. L’idée ici est que l’IA ne peut pas prévoir correctement le résultat de cas pour lesquels elle n’a jamais été entrainée. Par exemple, une IA de reconnaissance d’image qui n’aura été entrainées qu’à reconnaitre uniquement des chats et des girafes ne pourra jamais reconnaitre un cheval ou même un humain.
- Avoir des données non biaisées. Cet aspect est particulièrement problématique dans les IA actuelles car malheureusement les données sont généralement biaisées. Par biaisées, j’entends que l’ensemble du jeu de données propose une image erronée de la réalité. Ce type de jeu de données biaisées engendre des résultats faux et orientés. Je pense par exemple à une étude faite sur un IA utilisée aux Etats-Unis pour savoir si un criminel à plus ou moins de chance de récidiver. Il s’avère que cette IA peut être considérée comme « Raciste » car son taux d’erreur en défaveur (forte chance de récidive mais ne récidive pas) des personnes « noires » est nettement supérieur à son taux d’erreur en défaveur des personnes « blanches ». Nous pouvons également imaginer une IA dans le recrutement qui sélectionnerait plus facilement des CVs d’hommes que de femmes, de personnes avec des noms à consonance « française » plutôt qu’étrangère (comme mon nom Hage Chahine), ou même par rapport à l’adresse… Le biais dans les données est donc un problème majeur à prendre en compte et qui, malheureusement, reproduit et amplifie trop souvent des biais inconscients de certaines personnes.
Attention aux données utilisées !
Un autre point important lors de la sélection des données se trouve au niveau juridique ou éthique.
Peut-on utiliser toutes les données que nous le souhaitons ? Il est évident que nom. La loi RGPD est d’ailleurs là pour nous le rappeler. De même l’utilisation de données anonymisées n’est parfois pas suffisante pour empêcher de vraiment remonter à la personne. Dans ce cas-là il est impossible (voire interdit) d’utiliser des données de production.
Un autre point d’attention par rapport aux données utilisées est de ne pas « surentrainer » son modèle. Le surentraînement est généralement lié à un algorithme pas assez performant mais il n’en reste pas moins problématique.
Enfin, il existe des IA qui continuent à apprendre directement grâce à ses interactions en production. Dans ce cas les créateurs de cet IA n’ont aucun pouvoir (sauf avec un algorithme anticipant les problèmes) sur la manière dont l’IA va évoluer et cet IA peut devenir raciste ou antisémite (comme il est arrivé en moins de 24 heures avec une IA de Microsoft) alors qu’au départ elle avait été bien entrainée et représentait un bot parfaitement respectable.

Conclusion :
Les données sont la base de toute IA faisant appel à de l’apprentissage. Ces données doivent satisfaire à de nombreuses caractéristiques afin de proposer une IA performante. Il faut donc, lorsque l’on veut faire de l’IA, travailler avec personnes capables d’analyser (Data scientist) ces IA afin de bien nous conseiller dans notre démarche. Les équipes (agiles ou équipes de test) devront donc ajouter une nouvelle compétence si elles veulent être performante et utiliser ou proposer des IA.
Certains exemples sont tirés de la présentation de Laurent Bouhier à la JFTL 2019.
N’hésitez pas à me suivre et lire mes autres articles si vous voulez en apprendre plus sur le test ou venir partager vos connaissances
Merci à tous ceux qui mettent « j’aime », partagent ou commentent mes articles
N’hésitez pas à faire vos propres retours d’expérience en commentaire.



Une réponse