
« Un agent IA testeur ? Comment pourrais-je avoir confiance alors que je sais que les IA ne sont pas fiables ? »
Dans ce quatrième article de ma série consacrée aux agents IA d’exécution des tests manuels, j’aborde une question centrale pour les équipes QA : la fiabilité. Peut-on faire confiance à un agent IA testeur ? Sur quoi cette confiance peut-elle se construire ?
Si vous n’êtes pas familier de l’IA agentique et des agents IA visuels appliqués à l’exécution des tests, je vous recommande de lire les épisodes précédents de cette série. En partie 1, je présente les agents IA et leur usage pour l’exécution des tests. En partie 2, je détaille une illustration sur un exemple concret avec Lynqa for Xray développé par Smartesting (dont fait partie l’auteur de ces lignes). En partie 3, j’expose les deux voies de l’automatisation des tests par l’IA : l’IA agentique et les assistants IA de scripting et leur complémentarité
Les résultats présentés dans cet article sont issus des travaux menés au Lab IA de Smartesting depuis juin 2023, date à laquelle nous avons commencé à développer un agent testeur intelligent et autonome, à l’évaluer de manière rigoureuse, et à mettre en place des mécanismes destinés à en renforcer la fiabilité.
Votre IA fait des erreurs : voyons cela plus en détail !
Les modèles d’IA générative peuvent « halluciner », c’est-à-dire produire une réponse plausible… mais fausse. Ce n’est pas une anomalie de fonctionnement, ni un bug au sens classique du terme. C’est une caractéristique intrinsèque, liée à la nature même des algorithmes d’apprentissage et d’inférence des modèles génératifs.
Ce risque d’erreur est étroitement lié au caractère non déterministe de ces modèles : à une même demande, plusieurs réponses différentes peuvent être produites. Cela déroute souvent au début, puis on apprend à travailler avec cette réalité : garder un regard critique, vérifier lorsque c’est nécessaire, et adapter le niveau de contrôle au risque métier.
Cela n’empêche pas l’IA d’apporter des bénéfices réels, mesurables, et désormais largement observés dans de nombreuses activités professionnelles. Dans le domaine du test logiciel, les risques varient selon le cas d’usage.
Par exemple, lorsqu’on utilise une IA générative pour améliorer la formulation de user stories ou générer des cas de test, les principaux risques sont les suivants :
- Un résultat peu pertinent : la reformulation ne reflète pas exactement le besoin, certains cas de test générés n’ont pas de sens pour l’application, ne servent pas l’objectif de test, ou apportent peu de valeur.
- Un résultat incomplet : des critères d’acceptation critiques sont absents, ou des cas de test importants ne sont pas couverts.
Dans ces situations, la cause est généralement une faiblesse du context engineering : quel que soit le modèle utilisé, il a besoin d’un contexte projet précis, structuré et pertinent pour produire des résultats fiables.
Dans l’IA agentique appliquée au test, notamment pour exécuter des tests manuels, les risques sont d’une autre nature. Pourquoi ? Parce qu’un agent IA testeur agit sur le système sous test. Il ne se contente pas de générer du contenu : il exécute, observe, interprète, et décide d’un verdict.
IA agentique d’exécution des tests : quels sont les risques d’erreur ?
Ces risques sont de la même nature pour l’IA et l’humain. Un testeur QA comme un agent IA d’exécution de tests manuels peuvent :
- Ne pas parvenir à réaliser une action demandée par le scénario. Les causes sont connues : environnement incomplet, données absentes, action non disponible, ou difficulté à comprendre comment effectuer une action spécifique. Dans le cas des agents IA, ce point était une limitation importante encore récemment. Il s’est toutefois nettement amélioré avec l’enrichissement des outils mis à disposition des agents et les progrès des modèles dans la sélection et l’enchaînement d’actions. En pratique, la navigation applicative par un agent IA est devenue beaucoup plus robuste.
- Avoir un doute sur le résultat d’une étape et produire un faux négatif. Par exemple, le message obtenu est proche du message attendu, mais pas identique. L’étape est alors marquée en échec, avant qu’une revue humaine ne conclue que le comportement de l’application testée est acceptable.
- Ne pas détecter une anomalie et produire un faux positif. C’est le cas le plus problématique : le test passe alors qu’il aurait dû échouer. Tout testeur manuel en a déjà fait l’expérience. Certaines anomalies sont discrètes, certains attendus sont ambigus, et certaines situations sont faciles à mal interpréter. Un agent IA peut rencontrer le même type de difficulté.
L’introduction d’agents IA dans le processus de test soulève naturellement la question de la fiabilité et de la confiance. La confiance doit s’établir sur des faits, et pour un agent IA testeur, elle s’articule autour de trois piliers essentiels :
- Une fiabilité de l’agent testeur très élevée, mesurée par des métriques.
- La capacité de l’agent à interagir, à exprimer ses doutes et à enrichir ses connaissances.
- Une transparence de l’agent dans la conduite de ses actions et l’explication de ses résultats.
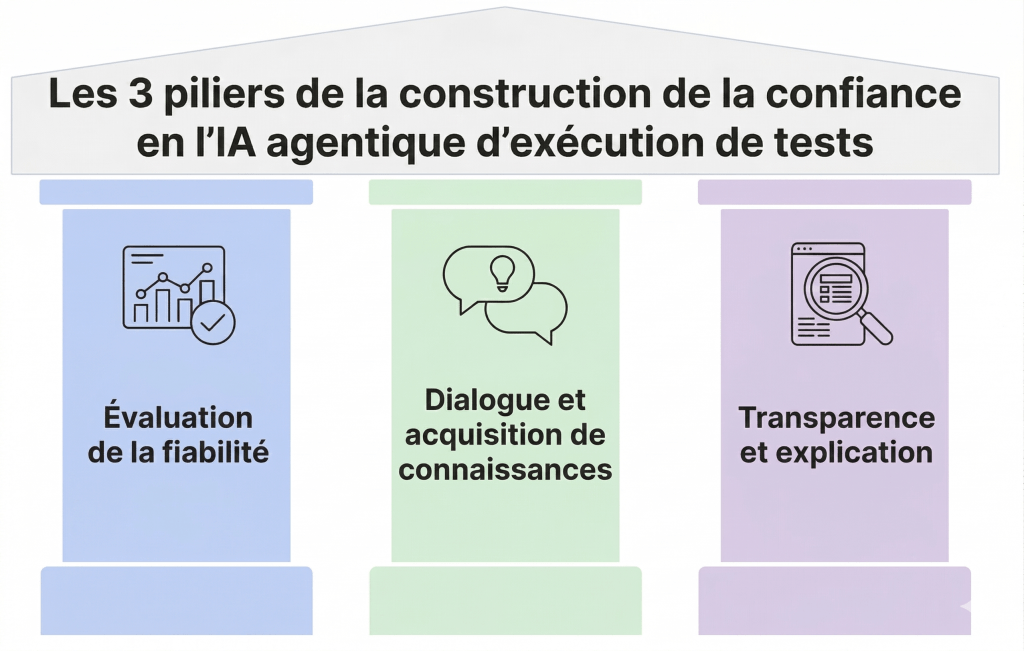
Pilier 1. L’évaluation de la fiabilité de l’agent testeur : un socle indispensable
L’évaluation d’un agent IA testeur repose sur trois composants :
- des jeux d’essai représentatifs ;
- des métriques d’évaluation automatisables ;
- une infrastructure d’exécution permettant de mesurer les performances de manière répétable.
Dans le domaine de l’IA, on parle de benchmark et de benchmarking. Un benchmark est un ensemble de cas annotés avec des résultats attendus, qui permet de mesurer la qualité d’un modèle sur une tâche donnée. Le benchmarking joue un rôle central dans la recherche en IA.
Un point important est à retenir : il n’existe pas aujourd’hui de benchmark public de référence pour les agents IA testeurs.
Le plus proche, et le plus utile pour situer l’état de l’art, est la famille des benchmarks dits computer-use, qui évaluent la capacité d’agents IA généralistes à interagir de manière autonome avec des applications, comme le ferait un utilisateur.
Les benchmarks OSWorld et WebArena, qui sont très complets et représentatifs, montrent une progression très forte des capacités des agents IA computer-use ces deux dernières années. Les meilleurs agents réussissent désormais une part importante de tâches complexes sur des environnements web, mobile, desktop ou système. Cette progression montre que la base technologique est désormais suffisamment mature pour être utilisée sur des cas réels, avec supervision humaine.
Tableau des résultats de l’IA à début avril 2026 sur trois benchmarks agentiques très complets:
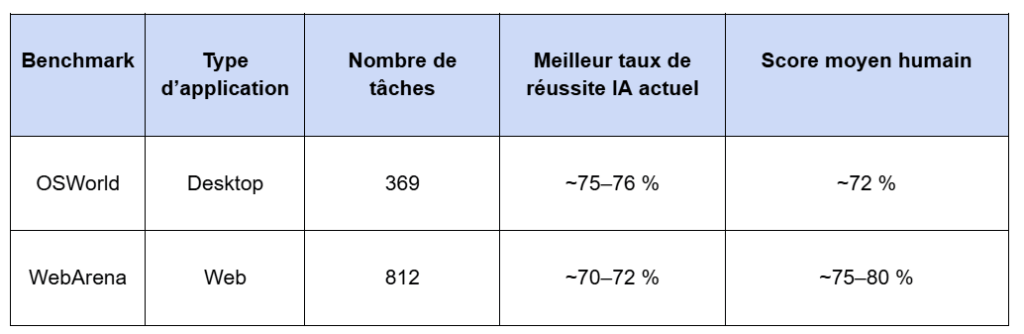
Comme tout benchmark, ces résultats peuvent présenter des biais (dans le choix des tâches), mais ils donnent une bonne indication du niveau actuel de la performance des agents IA généralistes.
Résultats observés pour les agents IA testeurs
Je ne peux pas parler ici de tous les agents en général. En revanche, je peux restituer ce que nous avons appris au Lab IA de Smartesting durant ces deux dernières années d’évaluation de notre agent Lynqa.
Par rapport aux agents généralistes, l’évaluation d’un agent IA testeur demande une attention particulière à deux points :
- le respect de l’intention de test exprimée dans le scénario ;
- l’évitement des faux positifs lors de la vérification du résultat attendu.
Pour évaluer un agent testeur, il ne suffit pas de regarder le résultat final : il faut analyser comment il exécute le test et comment il prend sa décision.
Un agent peut obtenir le bon résultat… mais pour de mauvaises raisons.
Sur nos benchmarks internes, construits de manière itérative et enrichis en continu avec de nouveaux cas représentatifs, les performances de fiabilité d’exécution dépassent 85 %.
Autrement dit, sur 100 étapes de test exécutées, plus de 85 sont jugées correctes, avec le bon verdict et la bonne explication.
Ce chiffre correspond à un taux moyen obtenu après plusieurs exécutions sur les jeux d’essai. Il prend en compte :
- la justesse du verdict sur chaque étape ;
- la qualité de l’explication produite ;
- l’absence de faux négatifs ;
- l’absence de faux positifs ;
- les cas où l’agent ne parvient pas encore à exécuter l’action demandée.
Nous retrouvons également ce niveau de fiabilité dans les exécutions réalisées par les utilisateurs de Lynqa, où les remontées d’exécutions erronées restent peu fréquentes.
En résumé, la fiabilité des agents IA testeurs repose à la fois sur les progrès rapides des technologies agentiques et sur leur spécialisation pour le test logiciel : respect des consignes, contrôle du verdict, prudence dans l’interprétation du résultat attendu.
La fiabilité est donc bien présente aujourd’hui, mais des erreurs subsistent. Elles proviennent principalement de deux causes :
- Certaines capacités manquent encore. Exemple : un scénario impose une vérification sur un autre appareil spécifique, comme une montre connectée. Tous les cas de test ne seront pas couverts par un agent IA, et c’est normal. Une équipe QA doit savoir définir le périmètre de validité de l’agent.
- L’agent interprète mal une consigne, en particulier un résultat attendu formulé de manière implicite ou ambiguë. L’erreur provient ici de l’interprétation de la consigne de test.
La réponse à ce second problème s’appuie sur la capacité de l’agent à ouvrir le dialogue avec le testeur QA et à apprendre de ce dialogue. Un agent de confiance doit savoir détecter lorsqu’il doute et solliciter l’humain lorsque l’interprétation n’est pas suffisamment sûre.
C’est le deuxième pilier de construction de la confiance.
Pilier 2. Le dialogue humain / IA et l’acquisition de connaissances : éduquer l’agent
Le principe est le suivant : un mécanisme d’observation analyse la trace d’exécution et les raisonnements de l’agent. Lorsqu’un doute significatif est détecté concernant l’interprétation d’une étape, une demande de dialogue est préparée à l’intention du testeur QA humain.
Ce dialogue s’appuie sur des choix proposés à l’utilisateur. La réponse humaine peut conduire :
- soit à la création d’une connaissance réutilisable par l’agent ;
- soit à une suggestion de reformulation de l’étape de test ;
- soit aux deux.
Le dialogue et l’acquisition de connaissances sur un exemple
Voici un extrait de dialogue et d’acquisition de connaissances sur un cas de test, volontairement imparfait, portant sur la section « Les plus lus » du site La Taverne du testeur.
Voici le cas de test :
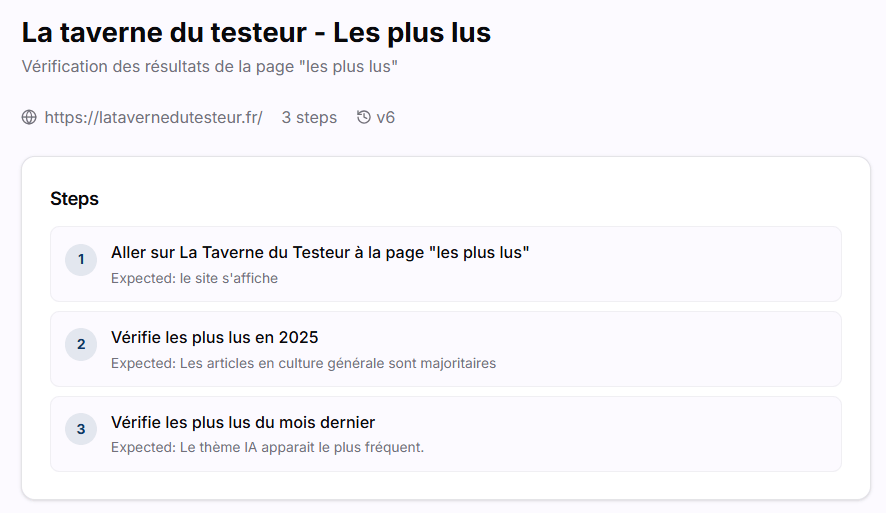
L’exécution de ce test a été réalisée début avril 2026, et la rubrique « les plus lus » du mois dernier est en fait celle du mois de février, comme le montre cette capture d’écran enregistrée par l’agent.
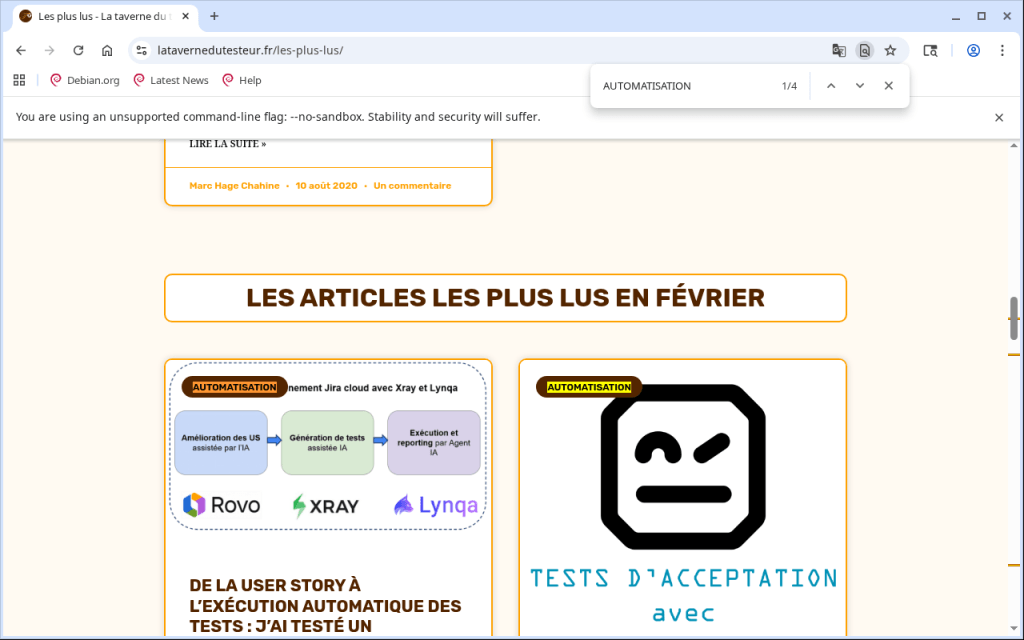
Lors de l’exécution du test, l’agent IA soulève une incertitude concernant l’étape #3 du test, ce qui se traduit par la demande suivante au testeur QA humain.
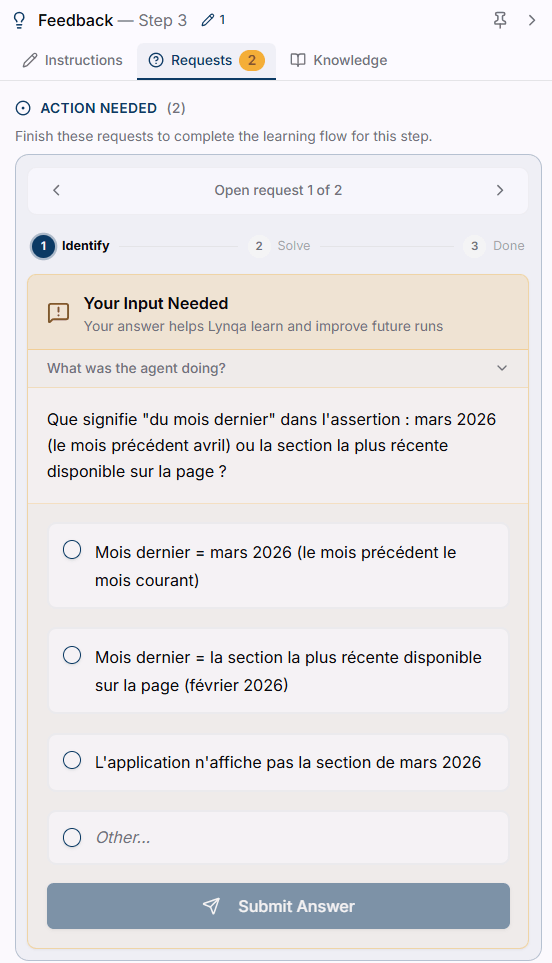
La réponse de l’humain ici est : « Mois dernier = la section la plus récente disponible sur la page (février 2026). ”. Le mécanisme de dialogue propose alors à l’humain de créer une connaissance dont voici le libellé : “Pour vérifier le contenu correspondant au « mois dernier », utilise la section relative au mois le plus récent effectivement disponible sur la page, et non le mois civil précédant la date du jour.”
Apports du dialogue et de l’acquisition de connaissances.
Dans l’exemple présenté, l’agent détecte une ambiguïté sur l’expression « le mois dernier ». La réponse humaine clarifie la règle à appliquer : il faut utiliser la section la plus récente effectivement disponible sur la page, et non nécessairement le mois civil précédent.
À partir de cette réponse, l’agent peut mémoriser une connaissance exploitable dans de futurs cas similaires.
La portée de cette connaissance peut être définie au niveau :
- de l’étape ;
- du scénario ;
- ou de la suite de tests.
Cette capacité à acquérir des connaissances permet à l’agent d’apprendre les conventions, règles implicites et préférences propres à l’équipe QA, et de s’améliorer au fil de son usage. En pratique, cela apporte trois bénéfices :
- la détection des situations ambiguës ;
- l’implication ciblée de l’humain uniquement quand cela est nécessaire ;
- l’amélioration continue du comportement de l’agent.
Un agent IA de confiance n’est donc pas un agent qui prétend tout savoir. C’est un agent qui signale ses doutes, partage ses incertitudes, et apprend des réponses humaines.
Sur nos benchmarks avec Lynqa, le dialogue et l’acquisition de connaissances permettent de traiter plus de 90 % des cas de doute détectés, ce qui élimine l’essentiel des mauvaises interprétations liées à l’ambiguïté des consignes.
Il existe des cas résiduels. Cela ne rend pas la technologie inutile pour autant. La question pertinente est celle du rapport entre gains obtenus et coût de contrôle humain, car un agent doit rester sous supervision humaine et il doit faciliter cette supervision.
C’est précisément ce qui amène au troisième pilier.
Pilier 3. La transparence des actions et l’explication des résultats pour faciliter la supervision humaine
Un agent IA testeur peut aujourd’hui exécuter des scénarios fonctionnels longs sur des applications riches, lever certains doutes via le dialogue, et capitaliser des connaissances utiles.
Mais il reste, et doit rester, sous contrôle du testeur QA humain. La décision finale sur l’acceptation du résultat d’exécution relève de la responsabilité humaine. Un agent de confiance doit donc être capable de rendre son activité lisible, vérifiable et auditable.
Pour un agent IA testeur, cela passe au minimum par deux niveaux de restitution :
- le détail des actions réalisées pour chaque étape de test ;
- l’explication du verdict produit, en lien avec le résultat attendu observé.
Dans un bon dispositif de restitution, le testeur doit pouvoir aisément comprendre :
- où l’agent a navigué ;
- quelles actions il a réalisées ;
- ce qu’il a observé à l’écran ;
- pourquoi il a conclu à un PASS ou à un FAIL ;
- quelles preuves soutiennent ce verdict.
Les captures d’écran jouent ici un rôle essentiel. Elles documentent les actions et les états observés, et facilitent la revue humaine après exécution. En cas d’échec, le commentaire produit par l’agent doit être encore plus explicite : il doit aider le testeur à distinguer un vrai défaut, une mauvaise interprétation, ou une simple limite d’exécution.
Voici un exemple de visualisation d’une étape de test avec capture d’écran remontée par l’agent IA Lynqa dans Xray :
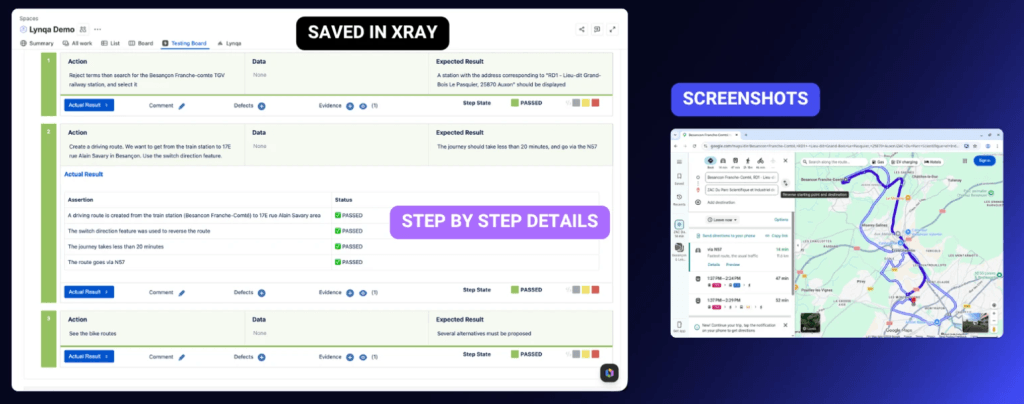
Un agent IA testeur doit être transparent quant aux actions effectuées sur le système testé et précis dans l’analyse du statut d’exécution de chaque étape. Les captures d’écran apportent des preuves des actions et des résultats obtenus lors de l’exécution. Cette transparence et l’explication permettent ainsi au testeur de passer en revue les exécutions et de décider de l’acceptation du verdict de test eainsi que de sa publication dans l’outil de Test Management.
Cette exigence de transparence des exécutions réalisées n’est pas spécifique à l’IA. Elle existait déjà dans les démarches de sous-traitance d’exécution de tests : lorsqu’une équipe QA délègue l’exécution, elle attend un suivi détaillé, des preuves, et la possibilité de revenir sur chaque étape en cas de doute. Avec un agent IA testeur, le besoin est le même.
Pour conclure
L’IA agentique appliquée à l’exécution des tests a progressé très rapidement en 2025 et continue de gagner en maturité en 2026. Les niveaux de fiabilité atteints sont suffisamment élevés pour justifier une évaluation sérieuse par les équipes QA.
Le dialogue humain / IA et l’acquisition de connaissances renforcent encore cette fiabilité en permettant à l’agent d’intégrer progressivement les règles implicites, les préférences et les conventions propres à une équipe.
Enfin, la transparence des actions, l’explication du verdict étape par étape, et la production de preuves d’exécution permettent un contrôle humain efficace.
Pour autant, chaque contexte d’usage reste spécifique. La bonne démarche n’est donc pas de croire sur parole aux promesses de l’IA agentique, ni de la rejeter par principe. La bonne démarche consiste à l’expérimenter en environnement représentatif. Pour évaluer un agent IA testeur dans votre contexte, il faut :
- Sélectionner des scénarios représentatifs de votre patrimoine de test ;
- Couvrir des niveaux de complexité variés ;
- Inclure des situations de test diverses ;
- Analyser les résultats obtenus, y compris les erreurs.
C’est ainsi qu’une équipe QA peut se forger sa propre opinion, fondée sur des observations concrètes, et déterminer le périmètre pertinent d’usage de l’exécution agentique.
En bref : essayer, mesurer, observer, pour maîtriser l’usage de l’IA agentique dans votre contexte.
À propos de l’auteur
Bruno Legeard dirige le Lab IA de Smartesting (éditeur de Lynqa). Expert en test logiciel et membre du CFTL, il contribue activement à la définition de la certification ISTQB CT-GenAI « Tester avec l’IA générative ».


